Introduction
I have been working in a project to enable anyone to fork and run a retrospective board in its own server. I have created 2 (two) projects: one for the UI with React and GraphQL using Apollo client and one for the GraphQL server also using Apollo (Server) and MongoDB for the database.In the following sections I am going to walk you through the steps and explain how to run both projects.

Main features
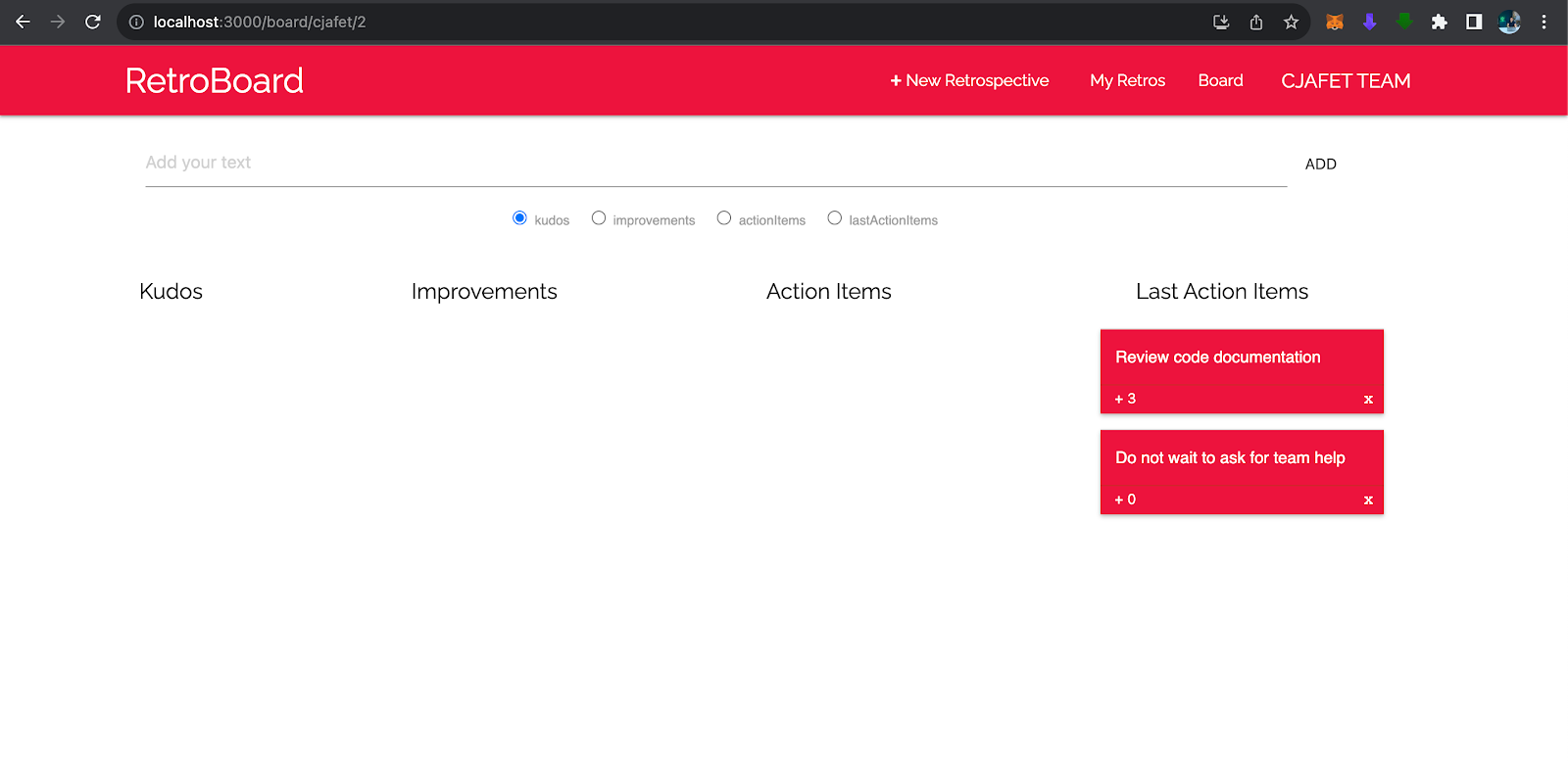
The board main features:- History of your past iteractions saved in the Mongo database
- Easy url link format to quick access any past iteractions
- Automatically add action items as last action items in the new board
- Quick move items to Action Items
Coming next
You can fork the React UI from the following GitHub repo:- Support for multiple teams
- Authentication
- Subscriptions (pub/sub)
Code Repo
You can fork the React UI from the following GitHub repo:React Retrospective UI
You can fork the GraphQL Server from the following GitHub repo:
Retrospective GraphQL Server
Running the React UI
Let's start by cloning the forked React UI repo:git clone https://github.com/cjafet/react-graphql-retro-board.gitNow change to the cloned directory and run the following command to install all project dependencies:
npm iWith all the project dependencies installed I will open the project in Visual Studio Code by running the following command in the terminal:
code .Run the following npm command to start and open the React board in the browser:
npm run start
You should see the following image since we don't have any boards yet and the the GraphQL server is not running:

Running the GraphQL Server
Next, let's clone and start the GraphQL server so we can create our first retrospective board!git clone https://github.com/cjafet/apollo-graphql-serverNow change to the cloned directory and run the following command to install all project dependencies:
npm iRun the following npm command to start the graphQL server:
npm run startWith our graphQL server running we can now create our first retrospective board!
Creating a new Retrospective
When doing this for the first time the UI will show a tex input so you can set your team name.

Conclusion
You can fork the react-graphql-retro-board and apollo-graphql-server projects mentioned in the beginning of this article to keep track of all of your team retrospective boards. The "My Retros" menu provide an easy access to all of your retrospectives saved in the mongoDB and you can also easily access any retrospective number by simpling following the board/team/retro# uri pattern. You can configure the application to use a cloud version of the MongoDB by simply going to the Atlas MongoDB Cloud website and register for a free trial.Github project
React Retrospective UIRetrospective GraphQL Server
References
GraphQL | A query language for your APIApollo GraphQL
MongoDB
MongoDB Atlas Database
Comments
Post a Comment